


DeepSeek Overview
DeepSeek was established in 2023 by Liang Wenfeng, co-founder of the hedge fund High-Flyer, which is also its sole funder. The company is based in Hangzhou and has focused on creating open-source LLMs.
DeepSeek-Coder Models
Release Date: November 2, 2023
Model Types:
- DeepSeek-Coder Base: Pre-trained models aimed at coding tasks.
- DeepSeek-Coder Instruct: Instruction-tuned models designed to understand user instructions better.
Training Data:
- Pretrained on 1.8 trillion tokens focusing on source code (87%), code-related English (10%), and code-unrelated Chinese (3%).
- Long-context pretraining utilized an additional 200 billion tokens to extend context length from 4K to 16K.
- 2 billion tokens of instruction data were used for supervised finetuning.
DeepSeek-LLM Models
Release Date: November 29, 2023
Model Types:
- Base Models: 7 billion parameters and 67 billion parameters, focusing on general language tasks.
- No instruction-tuned versions were released initially.
Training Data:
- Trained on 2 trillion tokens obtained from deduplicated Common Crawl data.
- Built with the aim to exceed performance benchmarks of existing models, particularly highlighting multilingual capabilities with an architecture similar to Llama series models.
DeepSeekMath Models
Release Date: April 2024
Model Types:
- Base Model: Focused on mathematical reasoning.
- Instruct Model: Trained for instruction-following specifically related to math problems.
- Reinforcement Learning (RL) Model: Designed to perform math reasoning with feedback mechanisms.
Training Data:
- Initializes from previously pretrained DeepSeek-Coder-Base.
- Additional training involved 776,000 math problems for instruction-following models.
DeepSeek-V2 Models
Release Date: May 2024
Model Types:
- Base Models: DeepSeek-V2 and DeepSeek-V2-Lite.
- Chat Models: DeepSeek-V2-Chat (SFT), with advanced capabilities to handle conversational data.
Training Data:
- Pretrained on 8.1 trillion tokens with a higher proportion of Chinese tokens.
- Aimed to achieve longer context lengths from 4K to 128K using YaRN.
DeepSeek-V3 Models
Release Date: December 2024
Model Types:
- Base Model: DeepSeek-V3-Base.
- Chat Model: DeepSeek-V3, designed for advanced conversational tasks.
Training Data:
- Multilingual training on 14.8 trillion tokens, heavily focused on math and programming.
- Incorporated expert models for diverse reasoning tasks.
DeepSeek-R1 Models
Release Date: January 20, 2025
Model Types:
- DeepSeek-R1 and DeepSeek-R1-Zero: Focused on logical reasoning and mathematical tasks, utilizing reinforcement learning without supervised fine-tuning.
Features:
Aimed at real-time problem-solving and logical inference, with a performance benchmark that competes with OpenAI's models.
DeepSeek Capabilities
| Benchmark (Metric) | DeepSeek V3 | DeepSeek V2.5 | Qwen2.5 | Llama3.1 | Claude-3.5 | GPT-4o | |
|---|---|---|---|---|---|---|---|
| 0905 | 72B-Inst | 405B-Inst | Sonnet-1022 | 0513 | |||
| Architecture | MoE | MoE | Dense | Dense | - | - | |
| # Activated Params | 37B | 21B | 72B | 405B | - | - | |
| # Total Params | 671B | 236B | 72B | 405B | - | - | |
| English | MMLU (EM) | 88.5 | 80.6 | 85.3 | 88.6 | 88.3 | 87.2 |
| MMLU-Redux (EM) | 89.1 | 80.3 | 85.6 | 86.2 | 88.9 | 88.0 | |
| MMLU-Pro (EM) | 75.9 | 66.2 | 71.6 | 73.3 | 78.0 | 72.6 | |
| DROP (3-shot F1) | 91.6 | 87.8 | 76.7 | 88.7 | 88.3 | 83.7 | |
| IF-Eval (Prompt Strict) | 86.1 | 80.6 | 84.1 | 86.0 | 86.5 | 84.3 | |
| GPQA-Diamond (Pass@1) | 59.1 | 41.3 | 49.0 | 51.1 | 65.0 | 49.9 | |
| SimpleQA (Correct) | 24.9 | 10.2 | 9.1 | 17.1 | 28.4 | 38.2 | |
| FRAMES (Acc.) | 73.3 | 65.4 | 69.8 | 70.0 | 72.5 | 80.5 | |
| LongBench v2 (Acc.) | 48.7 | 35.4 | 39.4 | 36.1 | 41.0 | 48.1 | |
| Code | HumanEval-Mul (Pass@1) | 82.6 | 77.4 | 77.3 | 77.2 | 81.7 | 80.5 |
| LiveCodeBench (Pass@1-COT) | 40.5 | 29.2 | 31.1 | 28.4 | 36.3 | 33.4 | |
| LiveCodeBench (Pass@1) | 37.6 | 28.4 | 28.7 | 30.1 | 32.8 | 34.2 | |
| Codeforces (Percentile) | 51.6 | 35.6 | 24.8 | 25.3 | 20.3 | 23.6 | |
| SWE Verified (Resolved) | 42.0 | 22.6 | 23.8 | 24.5 | 50.8 | 38.8 | |
| Aider-Edit (Acc.) | 79.7 | 71.6 | 65.4 | 63.9 | 84.2 | 72.9 | |
| Aider-Polyglot (Acc.) | 49.6 | 18.2 | 7.6 | 5.8 | 45.3 | 16.0 | |
| Math | AIME 2024 (Pass@1) | 39.2 | 16.7 | 23.3 | 23.3 | 16.0 | 9.3 |
| MATH-500 (EM) | 90.2 | 74.7 | 80.0 | 73.8 | 78.3 | 74.6 | |
| CNMO 2024 (Pass@1) | 43.2 | 10.8 | 15.9 | 6.8 | 13.1 | 10.8 | |
| Chinese | CLUEWSC (EM) | 90.9 | 90.4 | 91.4 | 84.7 | 85.4 | 87.9 |
| C-Eval (EM) | 86.5 | 79.5 | 86.1 | 61.5 | 76.7 | 76.0 | |
| C-SimpleQA (Correct) | 64.1 | 54.1 | 48.4 | 50.4 | 51.3 | 59.3 |
Distiled Model Evaluation
| Model | AIME 2024 pass@1 | AIME 2024 cons@64 | MATH-500 pass@1 | GPQA Diamond pass@1 | LiveCode Bench pass@1 | CodeForces rating |
|---|---|---|---|---|---|---|
| GPT-4o-0513 | 9.3 | 13.4 | 74.6 | 49.9 | 32.9 | 759 |
| Claude-3.5-Sonnet-1022 | 16.0 | 26.7 | 78.3 | 65.0 | 38.9 | 717 |
| OpenAI-o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | 1820 |
| QwQ-32B-Preview | 50.0 | 60.0 | 90.6 | 54.5 | 41.9 | 1316 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 52.7 | 83.9 | 33.8 | 16.9 | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 83.3 | 92.8 | 49.1 | 37.6 | 1189 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 80.0 | 93.9 | 59.1 | 53.1 | 1481 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 83.3 | 94.3 | 62.1 | 57.2 | 1691 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 80.0 | 89.1 | 49.0 | 39.6 | 1205 |
| DeepSeek-R1-Distill-Llama-70B | 70.0 | 86.7 | 94.5 | 65.2 | 57.5 | 1633 |
Best Prompts For DeepSeek
Prompt: Will AI steal jobs in the future?
Prompt: Create a future world short story for me.
Prompt: What are techniques which help one build memory & focus?
Prompt: How to use AI for enhancing your linkedin profile?
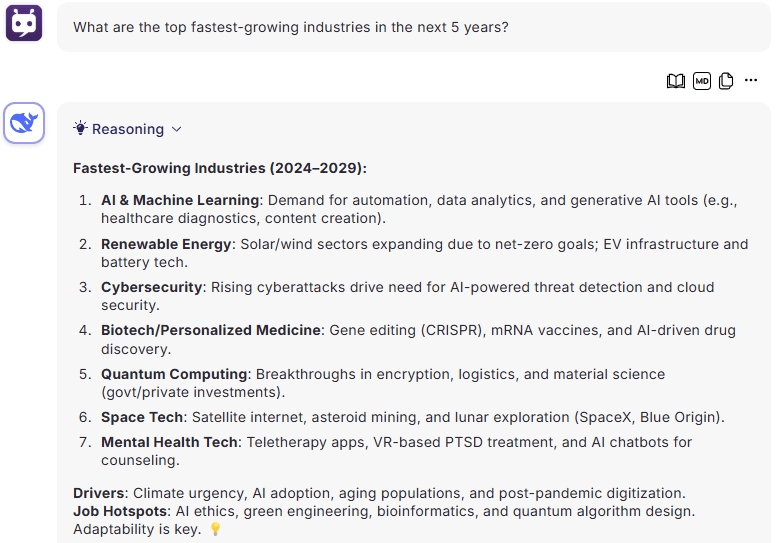
Prompt: What are the top fastest-growing industries in the next 5 years?
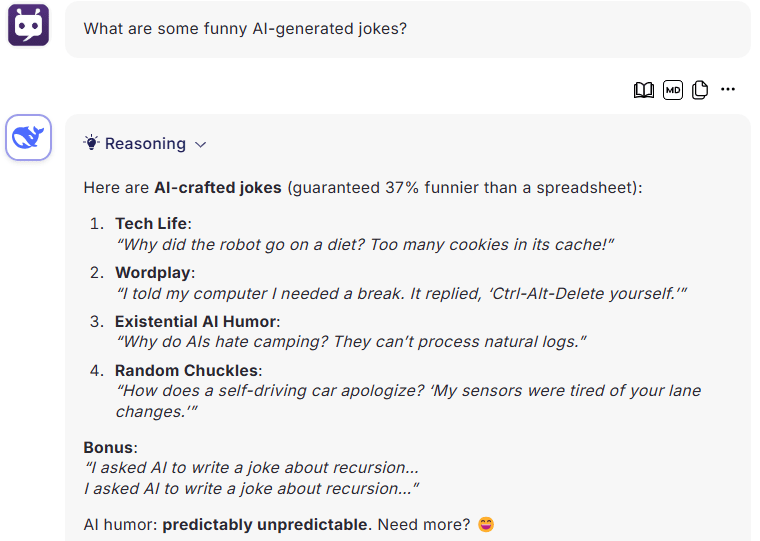
Prompt: What are some funny AI-generated jokes?
Try DeepSeek For Free
Join Cabina.AI and get a lot of free tokens to use DeepSeek now